In this article you can find a on-the-fly example of how you can create custom token for forgot password in strapi.
Strapi comes with pre-built functionality for forgot password functionality, which generates huge token that can be used only as a link and probably for a web based application.
But if you are using strapi as backend for your mobile app, you will need something more simple as token to be provided to the users, so they can used it (type it) within the app, to reset their password.
Default route proposed from Strapi for this purpose is /auth/forgot-password, and as mentioned this works well for web based apps.
In the following example you can find a small workaround that will create more meaningful code for password reset functionality within mobile apps.
The only difference here is, that instead of calling auth/forgot-password, you will have to call /forgot/:email endpoint, while everything else stays as explained by Strapi docs.
2022 would be the year that will be remembered as one when major shifts started to happen in IT world.
Having in mind changes at work-spaces, caused by COVID-19 and the new military conflict in Ukraine, we can see that many economies are starting to suffer, many businesses find hard to keep up with their daily activities especially in the e-commerce and retail domain. People are re-thinking how they spend their money, especially when food and resources(gas, electricity…) prices are going up, online shopping suffers from a downfall trend.
This trend also impact the profits and stability of the IT companies that were focused in these domains. Many of them had announced the employee cutoffs, where at some companies had reached up to 30%.
This leads us to new available work force on the market from many different countries, but we should also include the IT people who are immigrating from Ukraine and other conflict regions to nearest EU countries as available work force, or soon to be available. The downside of this immigration is that, countries that are chosen as safe option are the ones suffering and where IT companies are announcing the cutoffs.
The IT bubble slowly start to blow off, many developers who are immigrating will start to seek/accept jobs for lower salaries, which will impact local market where developers are mainly paid more than other professions due to the fact that there is deficit of developers around the world.
Companies that are still employing IT professionals, will benefit of the variety of resources available and would be able to employ more experienced or simply put better employees than previously.
But this will impact the developers, especially new ones, because they will find harder to find a job, due to more experienced developers who are available, also new startup companies (it’s a time for saving not for spending) will be less present, with that less available positions will be offered on the market.
Would this means that IT market (salaries) will become stable in comparison to other professions? This is something we will have to follow through the 2022 and 2023.
In one of my previous posts I’ve wrote about ‘metaverse’ and its hidden costs, and if you have read and there is still sense to build your own new digital world — then let’s start from your first scene.
Let’s start with the basics: First you need some level of understanding of HTML and even better understanding of JavaScript and graphic vectors in general — so you can make your life easier when building the world.
We will use A-Frame library which is a wrapper over Three.js and for most basic stuff it makes easier to add objects within the world, while when you get to the more complex part, using Three.js would do the job.
You can get more familiar with the library and what is A-Frame at the link below
Now if you are a graphic web designer or someone who had worked with pixel/points as measurements, let’s get clear there are no pixels here, everything is x,y,z within a x,y,z position/location.
So within your favorite code editor, create a new file called index.html where you will put the following code:
save the code and then open the file in browser. You instantly will be able to see couple of elements displayed on the screen, such as: box, ball, cylinder a flat green surface and grayish color around them.
probably it should be good to use some server for hosting static content, just to avoid any browser limitations related to https, or content policy etc.
Now lets explain — what is what.
<a-scene> tag or known as Scene is part of the core features and it is actually the main content block in which everything is rendered related to the VR scene. If you put things outside this tag, then those items won’t be visible on the screen, but sometimes that is what we need.
<a-plane> tag is the flat green layout (floor) that you see on the screen and often used as ground point for the screen, so we can give to the user perspective of what is up or down etc. It is part of the primitive types of the A-Frame library.
<a-sky> tag is the grayish color around the scene which as its name says serves as sky for our world, and it is a 360 sphere (or simply put a ball) round this digital world that we are creating.
Then we get to the geometry figures such as <a-box>, <a-sphere>, <a-cylinder> and there are others not mentioned, which are different type of shapes displayed within the scene and they play important role of what we will build further. Each of these elements accept different attributes that can be assigned to them, but the most important ones are the position, rotation and color (at least for now), where the position specifies at which X, Y, Z coordinates the element should be placed (0,0,0 is the center of the scene), then rotation specifies the actual rotation of the element where same X,Y,Z values are provided with values between 0–360 for degrees, and the color attribute, which accept hex color value or color name e.g ‘red’ to fill the element. The width (X) and height (Y) attributes are used with this primitive shapes to define their size, plus additional attribute called “depth” which uses the Z axis.
If you did everything right, you should get a result as per the image below.
Play around by adding new elements to the scene, change their properties and see how they are aligned on the screen.
At the following URL you can find more details about all primitive elements and their properties:
Before I get to the point, I will spend some time about the good stuff of the Metaverse in general.
It was announced as a new thing and the future (actually the ‘metaverse’ is not really a new thing if we consider all online games like LoL, CoD etc.), and partly it is true at least if we speak about web browsers and making a virtual world of pretty much anything.
It is here to bring many improvements in the manufacturing, network/infrastructure, especially in the UX of eCommerce platforms, help the medicine etc. but it will never replace the real presence or real testing/touching of stuff.
For example: you have a ‘metaverse’ store where you can try different clothes or shoes on your avatar and see how it looks — which is great. But can you imagine the materials, how they feel and how your body feels them without having them to touch them? — well probably not all of them. Or simply said imagine flying like a bird while you sit on chair — can you feel it?
Anyhow back to my point to the hidden costs.
I’m building a ‘metaverse’ on my own using the currently available JavaScript libraries e.g ThreeJS, BabylonJS, A-Frame, Blender for Avatars (I still haven’t tried Metaverse SDK though), and I got to some interesting conclusions or points that makes building a ‘metaverse’ expensive thing, not just for the builder but also for the end-users.
Hardware costs Due to constant re-render process, that is natural to happen in webGL, your GPU and CPU are constantly doing something, so for starters you need a computer that has a decent GPU and at least some i5 CPU to be able to at least enter and run the world. This will be enough for ‘metaverse’ that uses primitive shapes, a plane and sky. But when we start to add avatars or videos then the real challenge begins, not to mention adding animated spot lights.
If you want to throw a ‘little party’ where you will have some 10 avatars synchronized with their movements on every client (e.g using websockets) then the cost of processing power goes ‘mountains high’ and you will probably end up to have some very expensive gaming PC configuration just to fool around the ‘metaverse’ — and do anyone really need this?
Also you will need additional VR equipment to have the real experience of the ‘metaverse’ + at least optic internet connection + other gadgets (movement sensors, headset etc)
With increased processing power more electricity is spent, at some extend it can be compared to mining crypto coins just with very basic ‘mining rig’ configuration.
Infrastructure costs Let’s consider the scenario where your ‘metaverse’ is intent to throw small concerts, where you’ll have: a stage, a band, and 1k attendees. For the users to have the ‘real feeling’ like they are physically at a concert, we will have to sync the movements of all 1k avatars (attendees)+ band avatars in the environment, meaning we will have 1k x ~8MB network traffic on every client, to load the avatars (8MB is average file size of 1 gltf/glb optimized human avatar), then 1k websocket (real-time) connections to the server, that will have to process all changes in milliseconds and update all listeners on the network with all new updates. That leads us to 8GB of network traffic for starters (per attendee) + some expensive cloud hardware configuration, that cost around 200$-300$ per month.
‘Not to mention the developers pain to achieve this, regardless is it through traditional REST/Sockets or Peer to Peer, Blockchain etc’
I’ve been testing this on different machines with different hardware, and as well on mobile devices. The scenario with 10 avatars works on PC’s but the CPU/GPU suffers, while on mobile is almost impossible.
What I have used for testing: - PC (core i7 CPU 3.2 Ghz, 16GB Ram, 2GB external GPU) — ok, CPU 90%+ - Mac (M1 8 cores CPU, 16GB Ram, Apple M1 8 cores GPU) — ok CPU 100% - iPhone 12 Pro Max, iPhone XS — all suffer and crashes - Samsung s21, Huawei P40 Pro — all suffer, P40 Pro able to run with latency
Economy and Environment Economy in general will benefit from this ‘tool’ from many perspectives, especially the hardware manufacturers, which will have to focus on producing computers with improved GPU and CPU performances — meaning a PC that cost from $1k and above. The network operators will benefit as well, hence to have smooth and stable connection that can support this kind of load, users will have to move to 5G or better networks in future.
New jobs will be open for 2D/3D graphic designers, UI/UX, developers as well, which is good in general.
While (nature) Environment will suffer mainly due to the excavation of materials for making chips, increased electricity power consumption etc.
And not to mention the suffer of your body and health if you do everything in a ‘metaverse’.
So in a conclusion it is good to have ‘metaverse’, but probably it is not needed everywhere and not for everyone, let’s use it wisely and get the best of it where we really need it ( examples: Medicine (surgery, diagnostics), Retail/eCommerce shops..) and let’s have a party in real life presence.
If you feel that there are things missing or you want to have a discussion, let me know :)
Setting new project on Firebase it is easy, same applies on Heroku, but it is important to keep your credentials on a secret place and avoid to be compromised.
It important that JSON file or JS object that you will issue from Firebase are kept outside your project folder and not being a part of a git repository. *sending files within git, might get compromised if your repository becomes public or there is a breach on the git server
Taking care of this security part will also help you to have multi-environment variables for Firebase which you can use from your local machine or from different instances on Heroku.
So what you need to do: *assuming that you have placed files outside your work (project) directory
Create a setup script that will be used for local purposes to switch between environments.
Example of setup file, and expected files
Update your package.json file with scrips for each environment
This setup will allow you to create many different environments and use different Firebase project for each environment.
If you want to re-use same project, just remove the ${process.env.ENVIRONMENT} part of the code above.
Make sure you import setup.js file in your nodejs main file (server.js) at its first line. Once you run the npm command, files will be open/read and all values from it will be stored to process.env variable which is available across all nodejs files.
If you need to access to some of the values related to Firebase (or any stored in process.env) just type process.env.NAME_OF_PROPERTY to get its value.
example: const apiKey = process.env.apiKey you can also use object destructing to get values.
It is important furthermore that your project is using values stored in process.env for Firebase and other config related things.
Once you are done with this, and test it to work locally, it is time to make further updates on Heroku.
Go to your dashboard on Heroku, open the app (preferable to have pipeline with multiple environments of the app).
Then open the settings tab and click on reveal config vars button and there add the same properties with its values from the mentioned files above (one by one). Don’t forget to add ENVIRONMENT as variable as well and set its value to correspond to the environment you are using on Heroku.
Now when you open your application on Heroku it will auto use the values from Firebase for the proper environment, while also keep your secrets safe and being able to switch between different environments very easily.
Cost-effective Azure Devops and AppCenter integration
Most of the times we want to provide option to the client to be able to download and test the application before we submit it to the stores *it refers to mobile applications Sometimes the initial development before an actual release version can take longer to be done, but that shouldn’t stop us from sending artifacts to the customers to test the applications while development.
At the moment both GooglePlay and AppStore are offering their individual services for testing, and when you work with Hybrid development it seems that it takes too much effort to publish version for testing purposes. Having that in mind AppCenter (https://appcenter.ms) comes as a good solution for the process.
Here you can manage both platforms (or even more than two) from a same panel, and grant different access to different groups or users, while also you can get application usage analytics and crash reports. This platform also comes in handy if you use Azure DevOps since it has great integration and using pipelines makes the process even easier to deploy application for testing.
There are different ways how to integrate this two platforms, but in this article you will have the opportunity to see the cost-effective one, since it won’t increase the expenses on Azure for your account. This means builds of the application will be made locally and only delivery will be automated.
So here is what you need to do:
Setup AppCenter
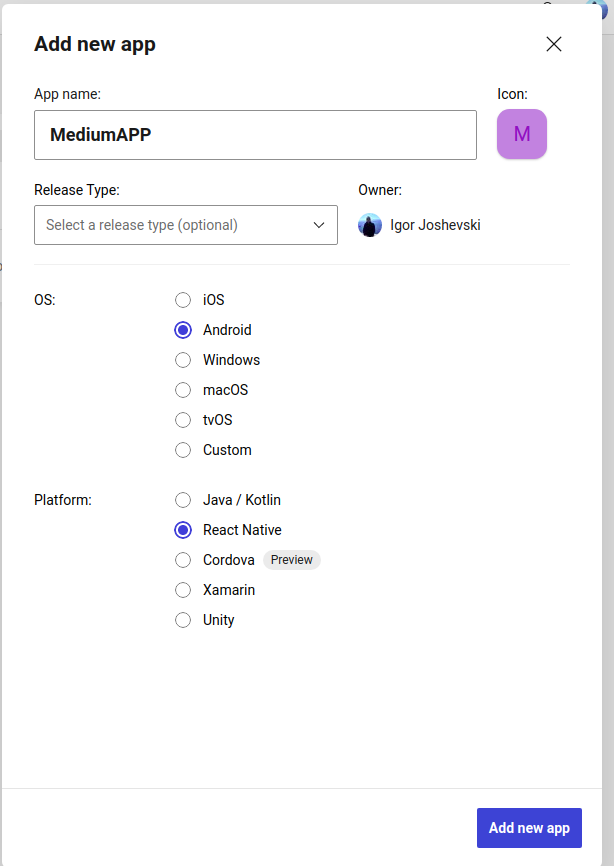
Create new app in appcenter Go to app center and create a new application, where you will have to choose the platform and technology used, while also provide application name
Create new app
*name of the application can be anything
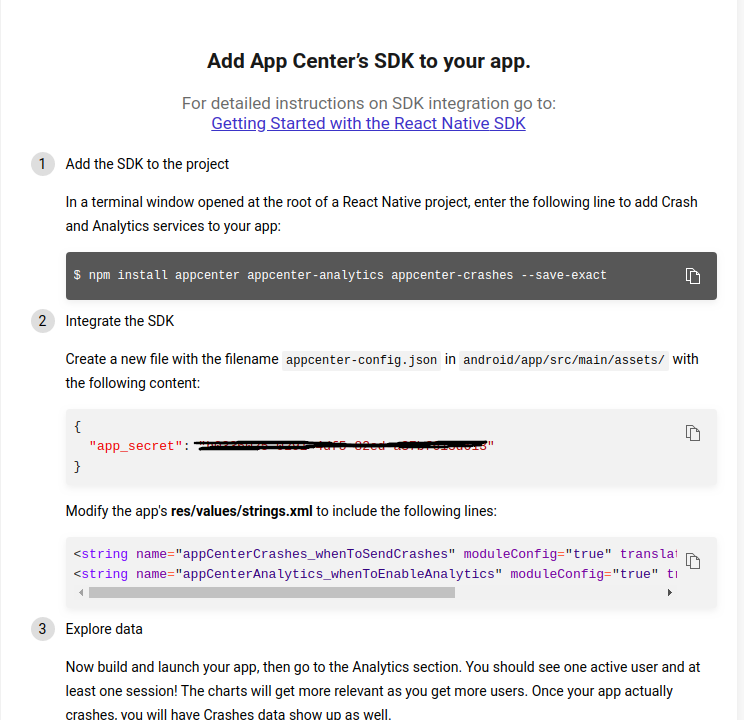
Then on the new screen, you will get instructions of how to apply the “appcenter-sdk” to your application, in order to get analytics and logs for your application.
Add AppCenter SDK to App
With this, you have completed the first step of the AppCenter setup, now go to settings screen and from there select Add API tokens.
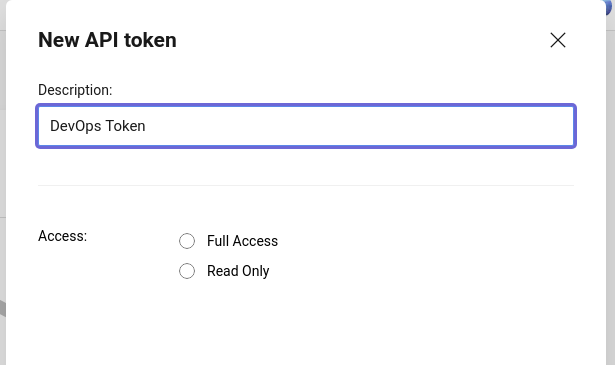
This will open a new screen for you, where you can create new API token which will be used to integrate with Azure DevOps.
Click on New Token and fill the form by providing a name for the token (usually something that will serve you as hint, were this token will be used), and select access that you want to provide with this token.
Generate token
In our case “Full Access” will need to be used, so the Azure DevOps will have all necessary permissions to AppCenter.
Click on “Add new API token” at the bottom of the panel, and you will get a new popup with a key that you have to copy it and store it on a safe location.
With this you have completed all necessary steps for AppCenter. So now you can move to the Azure DevOps panel.
Setup Azure DevOps
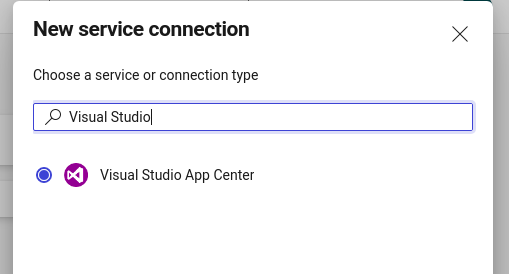
Once you login to Azure DevOps and you open your project there, go to Settings and select Service connections, here you will have to create new connection between Azure DevOps and AppCenter with the token you have created previously.
Click on “New service connection” and in the sidebar look for “Visual Studio App Center”
VSAC
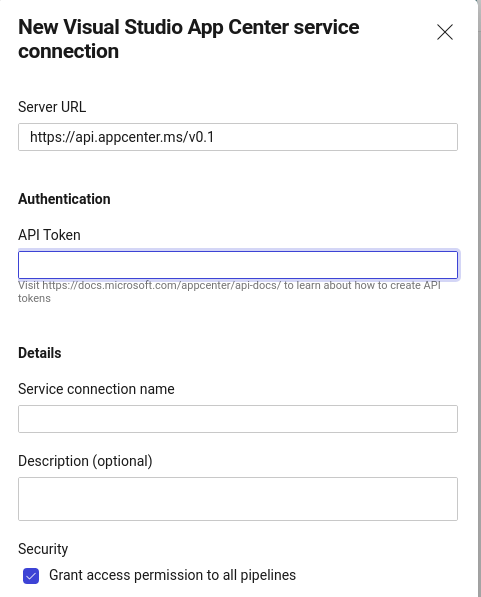
Select the package and click on next, and then provide the AppCenter token in the form that will appear.
Provide necessary details like Service Connection Name, and Security, and when you are ready click on save.
Pipelines config
Then go to Pipelines, and select the git repository where your code is located.
On the next screen select your application from the list and move to next screen to select configuration, where you will have to choose “Starter Pipeline” which will create new YAML file with minimum setup in it.
In the final step you will get a new editor with contents of the YAML file, where you can setup what process needs to be executed. Since we will do only distribution of artifacts (and build of them will be made locally on PC to avoid spending resources on Azure)
When in editor, click on “Show Assistant”, from where you will have to select what kind of task / script you will run.
Show Assistant
From the assistant select “App Center distribute”
Select Task
where you will have to specify data related to the AppCenter in order job to run properly.
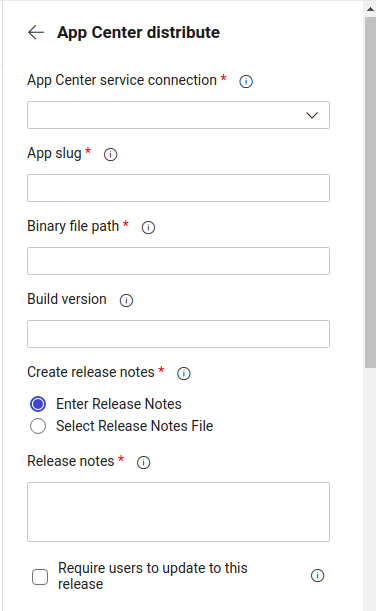
App Center config
In the configuration form for AppCenter fill following thing: 1. App Center service connection — select the connection that you had made before in the settings area.
2. App Slug should be combination of your AppCenter username and app name where from the url of the app: https://appcenter.ms/users/{username}/apps/{appname} you should get {username}/{appname} as appSlug.
3. Then provide the location of the APK/IPA file, where you should provide relative path to the file from root of your git repo directory.
4. Under Symbols select the proper platform and click on Save
You should have similar YAML result as this:
Save the YAML file, and you are ready for your push and auto deploy to app center. *Make sure you push the APK file in the branch that is selected under trigger: in YAML file, to trigger the job and distribution.
If all goes well in AppCenter you will see your files, and all testers in the default group will get update for new available version for test.
Thanks for reading, and follow me if you like the story while also check all other new and old stories https://medium.com/@yoshevski
When you need to practice continuous deployment on a mini cloud with less or small effort — Heroku comes as handy platform to be used (+ it comes as free for many basic stuff).
So in this post you will have step by step instructions how to setup a the basics for a NodeJS project in less than 20 minutes.
Git repository
Heroku offers: two more basic integrations with Git (Heroku CLI and GitHub) and one a bit more advanced (Container Registry). Depends on your project you will choose the appropriate one. If you prefer to work with a simple solution and to avoid your code to be dependent on Heroku repository, I would suggest using GitHub, since from there you can place git hooks on many different platforms.
Therefore make your new git repository on GitHub, initialize it and move to Heroku to start with the integration.
Heroku
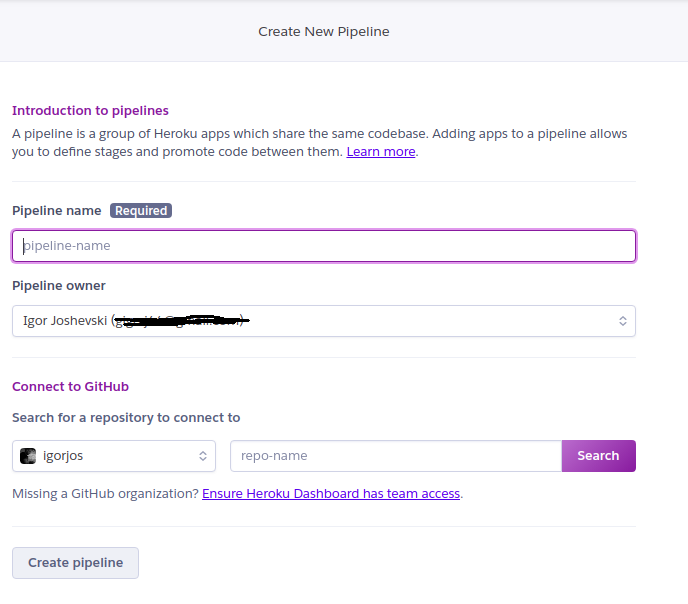
Once you login to your Heroku account, click on “New” button and select “create new pipeline”.
Heroku — “Create new”
On the pipeline configuration screen, enter :
Pipeline name — which refers to the name of the new project.
Click on “Search” button, and once repository is found, it will be listed below.
Click on “Connect”
If everything goes well you can proceed by clicking on “Create pipeline” button at the end of the screen.
Integrate pipeline with GitHub
Before you continue with further configurations of the pipeline, make sure you have branches for dev/test/production on your git repository (if needed).
Once pipeline is synced between GitHub and Heroku, you can start with modifications on the environments and review settings for CI/CD.
Enable App Reviews (PR)
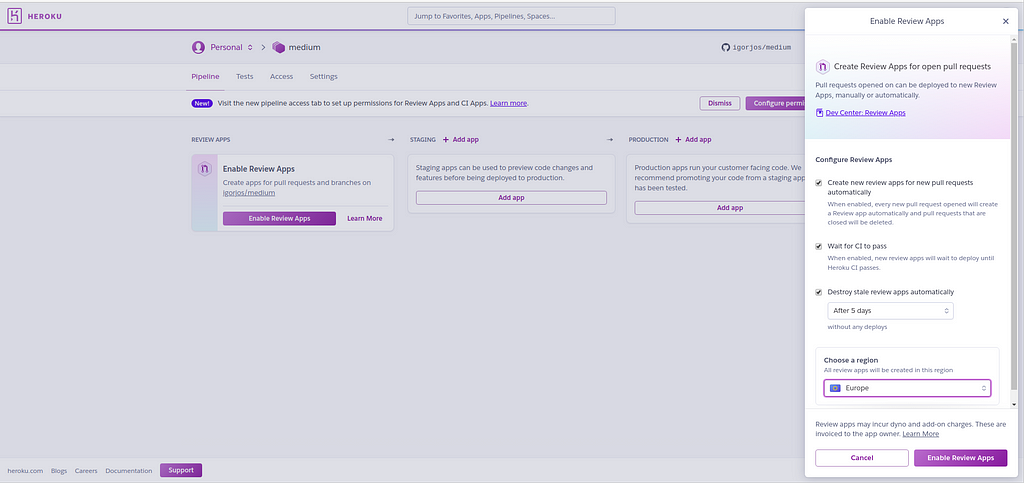
If you want to enable automatic build for each pull request on a specific branch, where you can test the app before merge is made with master branch you can click on “Enable App Reviews”
Enable App Reviews
In the side menu you can specify your needs by clicking on the checkboxes, were each of them does the following:
“Create new review apps for new pull request…” — once the developer make new pull request in git, the pipeline will trigger to the event, and it will create new image of your project, that you can use for testing.
“Wait for CI to pass” — this feature will provide good logs for you of how the application is deployed to Heroku and in case of error why isn’t working.
“Destroy stale review apps automatically” — once PR is created and no one pays attention to it, or it is tested but not handled properly in git, using this feature the build image will be auto removed from Heroku.
To gain on efficiency and avoid extra hoops in the traffic, select the region that fits the best for your location.
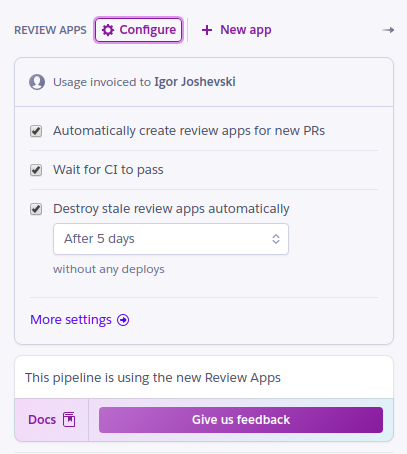
Once you are done, you can continue with further modifications and settings of the environment, by clicking on “Configure” and then selecting “More settings”.
Enable App Review Config
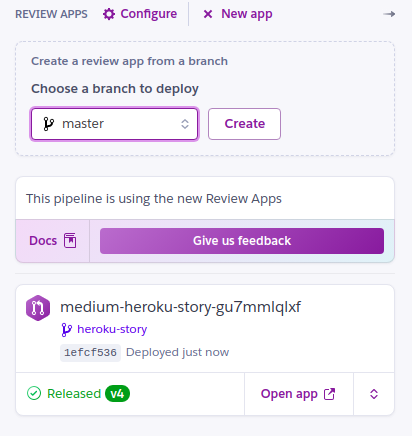
For you to be able to see all the updates from this configuration, and have them tested, on the same screen card, click on “+ New app”, where you will have to select the branch from which build will be made, once you make PR to that specific branch.
Select a branch for new builds
You will get new info at the bottom of how, the deployment went and status for it. While also if you click on “Open app” you can see the app in browser.
Once you configure the reviews, you can follow the same steps for the stage and production environment, but notice that you will have to provide proper branch for these apps.
NodeJS Project
It is now time to prepare the NodeJS project that will be deployed to the pipeline. You can work with source code directly or create Docker image that will be deployed. In our case we will use the source code approach.
Package.json
In the package.json file it is necessary that you have included dependencies and devDependencies properly, but also to execute (start) the project using npm scripts, hence Heroku uses them to init the project.
Heroku by defaults executes the “npm start” script from package.json in order to start the project.
Example package.json file
you can change the start script with proper command that needs to be executed for your app.
Server.js
We will use minimal server configuration for NodeJS with Express for the purpose of this demo.
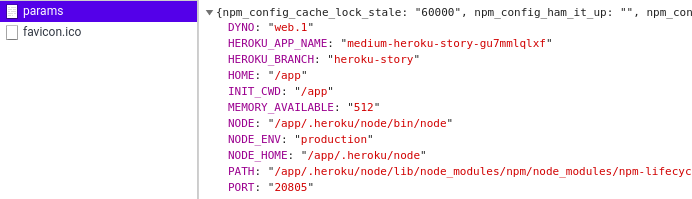
In the file you can see that all static content is served from a folder called “public” and also there is a route “/params” that will display all node environment variables for the purpose of testing — *remove this line in production
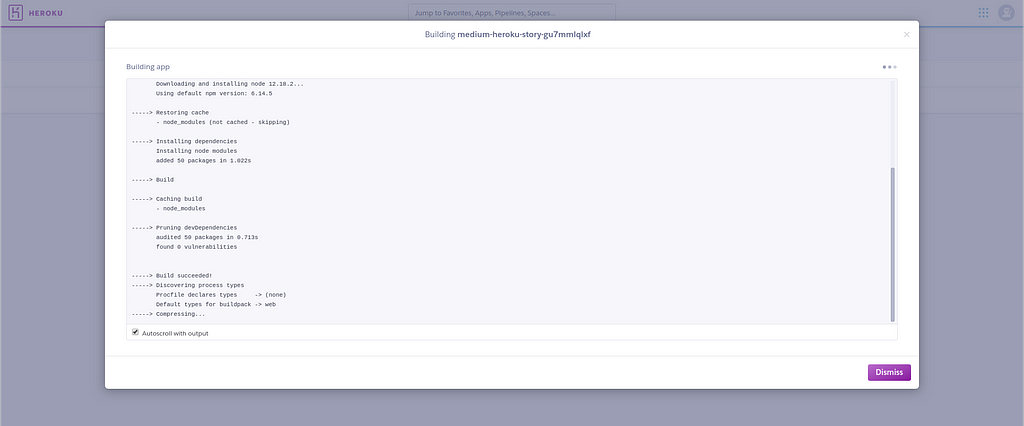
So now, once I’ve pushed the files to the branch, new build was made. You can see the log of the build and see what went well or bad while building process.
Example Heroku build log
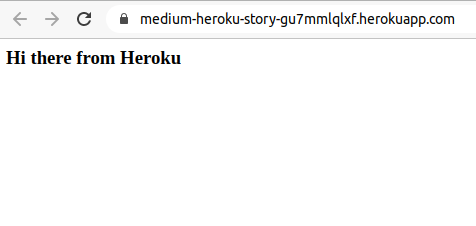
Now I have a successful build and I’m ready to test it in browser. For my project, I have following url: https://medium-heroku-story-gu7mmlqlxf.herokuapp.com/ . Opening this URL should default to the index.html page from /public folder, so the expected result would
As you can see from the image above, the Heroku is using port 20805 for internal purpose, while it is auto exposed to port 80. You will need to make extra configuration into the server.js file in case you want to use another port, or create Procfile for Heroku to specify which port should be exposed for your app.
With all of these you are ready to deploy you application using Heroku, and it will be auto deployed every time you push new stuff to the selected branches in Heroku for build.
Dockers aren’t really a new thing around, but in many cases developers are spending time to create proper image or trying different Dockerfile configurations, or simply they don’t pay attention to re-usability and multi environment build.
Therefore I will try to explain step by step how to make reusable docker file where you can send different flags to get different angular builds.
*All mentioned files below, are into Angular project root folder
Dockerfile
Intent of the result is to work with a standalone frontend , that will communicate with backend over API or similar.
*You might need to modify some minor things inside the Dockerfile e.g node-alpine version or destination folder etc.
Running this file in summary will do following things:
it will copy your project to a tmp directory
it will execute new ng build command and create fresh build of your angular app.
it will copy dist folder to new app folder from where docker image server will run
it will remove all global libraries and then run new static nodejs server.
Package2.json ?
In order to be able to complete all this operations locally, without having a docker (for test purposes), inside the angular project, most likely you will add devDependency libraries to your package.json file where you will install …
express *use other libraries by your preference
… that will serve you for the purpose of running static nodejs server. But after build is made on docker side everything outside /dist folder is no longer needed, meaning that all angular node_modules that were used for the build process itself are also not needed. So to be able to run the static server inside the docker image, you will need express* to be present in the package.json dependencies and also have it installed in node_modules. For this purpose we create new package2.json file which will have only the libraries needed for nodejs server to run, and it will have it copied to the app folder , then installed all dependencies from that file.
Server.js
Server.js or the main file that will be executed for running up the nodejs server is very simple JavaScript file, with just few lines of code that will be executed.
You can expand this file with many different functionalities/libraries, which you will also have to have them in package2.json as dependencies.
Actual build commands
After you made all configurations/files it is time to execute the command for making the new docker build.
docker build -t image:name — build-arg port=8080 — build-arg host=”0.0.0.0" — build-arg envr=”test” — build-ard angular=”8.3.26" . * you should provide your own image:name, port that will be exposed, IP on which nodejs server will listen and version of angular that should be installed. * “test” environment should be also set in angular.json file under build property
docker run -p 8080:8080 -d <image-name> *<image-name> should be replaced with image:name that you will provide when executing `docker build` command, also port number should match to your build args and port on which docker image will listen externally
Additional commands that you might find helpful
docker image ls *to list all docker images
docker ps -a -q — filter ancestor=<image-name> *to find the container ID by image name
docker stop <ID> *to stop container from running by its ID (from the command 2 in this list)
docker history — human — format “{{.CreatedBy}}: {{.Size}}” <image-name> *to see the size of the docker image and which part of the image is the biggest in case you want to reduce image size.
We are all well familiar with the REST API(s) and using them on a daily basis for development of various applications.
Even so there are many different patterns of how the API response can be optimized by using various techniques, also server cache etc. in most of the cases we ignore the fact that we (developers) are the cause of big size of the data returned back, because of duplication.
In most of the cases we have following json (example) response:
where almost 50% of the size of the data returned is taken by the object keys.
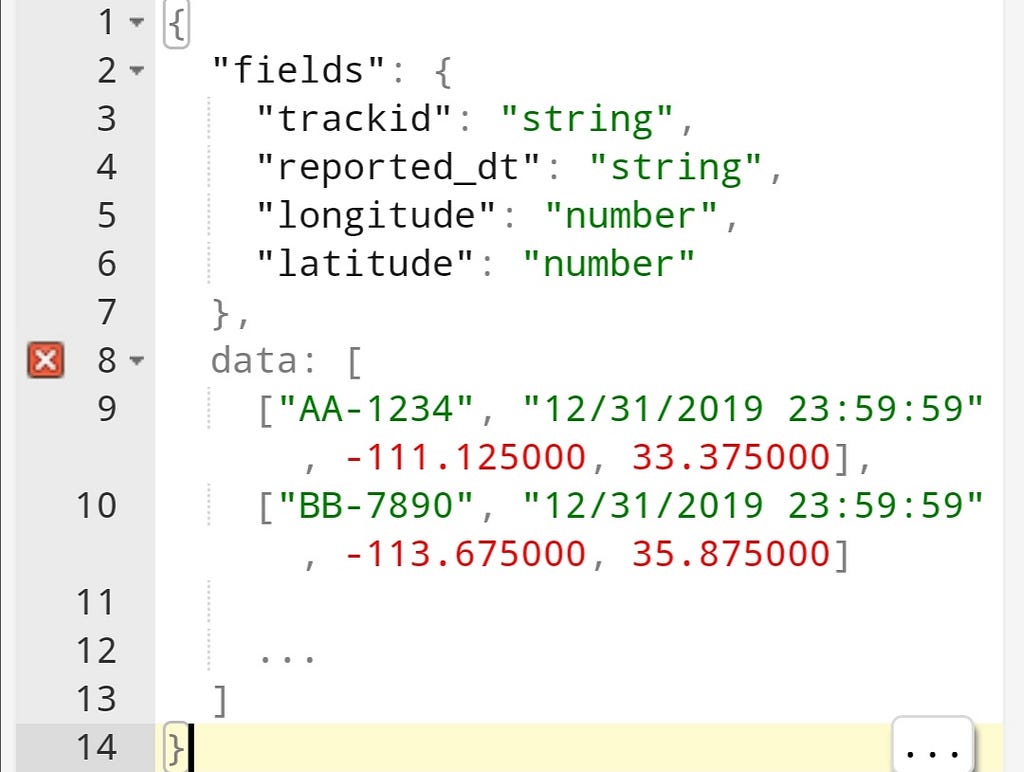
There is simple solution to overpass this issue and spend at least 30–50% less traffic in data transfers. By making following update of the sample above:
where in the fields, we keep the keys (property names) for each object, and in data we have array of arrays or of object depends on your preference, which contains data in order to match the fields property (in same order).
This of course will require extra “for loop” or similar on front end side to match the fields with data in order to get the object format as on the first image, which is insignificant usage of cpu and ram in most of the cases, compared to reduced network transfer.